Python 机器学习 - 预测分析核心算法(3)
Python 机器学习 - 预测分析核心算法(1) Python 机器学习 - 预测分析核心算法(2)
第四章 惩罚线性回归模型
惩罚线性回归的优势
- 模型训练速度快 在特征提取、数据预处理的阶段,训练速度非常重要。在某些场景下,如面向金融市场的自动交易模型, 训练速度也会影响应变的速度。
- 能得出变量的重要性 通过线性回归结果的系数,可以看出变量对结果的贡献度,哪些变量更加重要
- 预测速度快
- 对于样本不明显多于属性的矩阵、稀疏矩阵,或者模型解是稀疏解的情况,性能好。
何时使用集成方法
集成方法对复杂问题(如不规则的决策曲面)或者可以利用大量数据进行求解的问题, 表现较好。同时,集成方法能发现 2 阶甚至更高阶的重要性信息。
线性惩罚回归:对线性回归进行正则化以获得最优性能
设我们预测的值为 Y,一个列向量 Y=[y1, y2, y3, … yn] 设属性值为属性矩阵,每一行为一个样本
x11, x12, … x1m
X = x21, x22, … x2m
…
xn1, xn2, … xnm
所谓线性模型,就是寻找一系列的参数 ß1 ~ ßm 和一个标量 ß0 用 y = x1 * ß1 + x2 * ß2 + … + xm * ßm + ß0 来描述预测值与属性值之间的关系。
训练线性模型
普通线性模型就是求使得 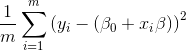 值最小的 ß 值
值最小的 ß 值
岭回归在线性关系中增加了一个惩罚项 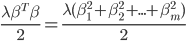 ,其中 λ 是可控的,从 0 到正无穷,
如果是 0 ,就相当于无系数的线性回归,如果是正无穷,则抛弃所有属性项,只留下常数项。
除了岭回归之外,还有其他的乘法项可选,比如套索回归,套索回归的惩罚项为
,其中 λ 是可控的,从 0 到正无穷,
如果是 0 ,就相当于无系数的线性回归,如果是正无穷,则抛弃所有属性项,只留下常数项。
除了岭回归之外,还有其他的乘法项可选,比如套索回归,套索回归的惩罚项为 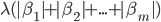
套索回归更倾向于导致稀疏的系数向量
向前逐步回归算法
- 将所有 ß 的值设置为 0
- 在每一步中
- 使用已选择的变量找到残差
- 确定哪个未使用的变量能够最佳地解释残差,将该变量加入选择变量
最小角度回归算法
- 将所有 ß 的值设置为 0
- 在每一步中
- 决定那个属性与残差有最大关联
- 如果关联为正,小幅增加关联系数;如果关联为负,小幅减少关联系数
用线性方法求解分类问题
- 二分类问题,将预测的两个分类映射到两个数值上,如 0 和 1
- 多分类问题,组合多个二分类器来获取结果
- 属性值为非数字,将一个属性列拆分成多个取值为 0 或 1 的属性列
使用线性方法解决非线性问题
通过基扩展的方式处理,在原始数据列中,加上包含非线性关系的数据列,再进行线性回归 如添加一列数据,值为 x1 * x2 或者 x1 的 n 次方,把这些包含了非线性信息的数据作为一个数据项, 然后用线性的方法检查其在预测中的相关性。