Python 机器学习 - 预测分析核心算法(2)
第三章 预测模型的构建:平衡性能、复杂性以及大数据
函数逼近
函数逼近问题的目标是,构建以特征作为输入的函数来预测目标变量。
特征通常以矩阵的形式表示
x11 x12 ... x1n
x21 x22 ... x2n
X = ... ... ... ...
... ... ... ...
xm1 xm2 ... xmn
预测目标值通常用向量 Y 表示
y1
Y = y2
...
ym
回归问题的本质就是寻找一个预测函数 pred(),使用它来预测结果
yt ~ pred(xt)
评估预测模型的性能
好的性能意味着使用属性 xi 来生成一个接近真是 yi 的预测。
1.对于回归问题,yi 是一个实数,性能用均方误差(MSE)或者平均绝对误差(MAE)度量 2.对于分类问题常用性能指标是误分类率
影响算法选择及性能的因素 — 复杂度与数据
- 对于列数比行数多的数据集(即数据不足的情况)或者简单的问题,倾向于使用线性模型。
- 对于行数比列数多很多的复杂问题,更倾向于使用线性模型
- 线性方法比非线性方法训练时间短
度量预测模型的性能
对于回归问题,均方差(MSE),平均绝对误差(MAE),均方根(RMSE/标准差)等数据都很有意义。 如果预测错误的均方差和目标方差几乎相等,或者标准差与目标标准差几乎相等,说明预测算法效果不好。 对于分类问题来说,一般使用混淆矩阵或者列联表来安排可能的结果输出。
ROC 曲线
ROC 曲线绘制真正率随假正率变化的情况。
- 一个理想的分类器,ROC 曲线应该是从 [0,0] 到 [0,1] 到 [1,1] 的折线
- ROC 曲线越贴合左上角表示效果越好
- AUC 表示 ROC 曲线下方的面积,可以用于评估分类器的性能,一般来说训练集上的效果会比测试集的好
ROC 曲线代码示例可以参考这里
n 折较差检验法
n 折交叉检验就是将数据分为 n 份,进行多次训练,每次选取一份作为测试数据其他的作为训练数据。
- 交叉检验法以更多的训练时间为代价,获取更多的训练样本。
- 如果数据量足够,预留小部分数据不会有太大影响,预留固定数据速度会快很多。
- 须要注意数据抽样过程中的统计规律,如果有必要,需要使用分层抽样,保证稀疏事件的比例。
模型与数据的均衡
最小过拟合的问题
设 Y 为目标向量,X 为特征矩阵,那回归问题就是寻找一个权重向量 ß,和一个标量ß0,对 Y 进行逼近
Y ~ Xß + ß0
如果 X 的行数列数相等,且不同列之间相互独立,X 可以求逆,那 ~ 可以替换成 =。 得到的向量会精确地拟合目标,但是过拟合严重。
过拟合的根源在于 X 中有太多列,可能须要去掉 X 中的一些列, 去掉哪些列的问题又称为最佳子集选择。
最佳子集选择
通过组合所有的列数可能,分别算出结果(包括所有1列子集,2列子集到 n 列子集) 取效果最好的子集。缺点在于特征列的组合太多,运算量非常大。
向前逐步回归
向前逐步回归是最佳子集选择的改进版。先对所有1列子集训练,然后使用其他列与 1 列子集中的最优列组成 2 列子集训练,而不是训练所有的 2 列子集。 最后产生多个具有不同复杂度的模型,选取其中最优的。模型越复杂,泛化能力越差。 一般来说,如果特征添加带来的性能提升只打到小数点后 4 位,保守起见可以将这样的特征移除。 代码可以参考这里
岭回归
岭回归通过惩罚回归系数来控制过拟合,普通最小二乘法的目标是找到让
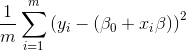 最小的 ß0 和 ß
最小的 ß0 和 ß
岭回归是一种乘法系数回归,是把系数变小而不是设为 0。岭回归对最小二乘法进行了修改,
变成求使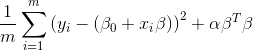 最小的 ß0 和 ß
最小的 ß0 和 ß
如果 a = 0,问题变为普通的最小二乘法,如果 a 变大,ß 接近于 0,那么就是仅通过常数项来预测目标。
使用 python 进行最小二乘法线性回归
from sklearn import linear_model
dataLinesModel = linear_model.LinearRegression()
# 进行训练
dataLinesModel.fit(xTrain, yTrain)
# 进行预测
predictions = dataLinesModel.predict(xTest)