从二叉树到 R 树
今天突然遇到一个数据库索引相关的问题,就顺便看了一下索引相关的原理,毕竟之前没有怎么了解过。 看到了些没看过的结构,还挺有趣的。
二叉搜索树
要维持一个有序索引,以提供快速的检索、插入、修改、范围查找功能,像链表这样的线性结构是不可能的了。 用二叉树代替索引的思路很自然,通过节点链接的分叉,压缩了每次查找时的路径长度,实现上也很简单。
普通的二叉树在正常情况下都可以工作得很好,但有个很严重的问题,那就是二叉树失衡。当数据是按顺序插入时, 二叉树虽然每个节点都有两个分支,但永远只有一个会被用到,也就是说退化成了链表。
平衡二叉树
为了保证二叉树的性能,须要一些额外的工作来保证它的平衡。平衡二叉树的方法有很多, 感觉最有意思的思路是 2-3 平衡树还有红黑树,将树的生长方向从树叶转化为树根,从而避免了失衡。 特别是红黑树,通过几个旋转操作,就能把 1 个二叉树变成 2-3 平衡树。
平衡二叉树解决了普通二叉树在特定情况下的性能问题,作为简单的索引应该是够了, 但如果用来作为数据库的索引,还是会有问题。那就是,二叉树的索引查找,并不是顺序寻址的, 每一次跳转都要进行磁盘 IO,成本很高。
B 树与 B+ 树
2-3 平衡树其实是一种多叉树,那很容易想到通过增加分叉数量来压缩树的高度,以减少每次检索的磁盘开销。 而 B 树,就是一种多叉树,只不过分叉数很多。
而 B+ 树是 B 树的一种变形,更适合用于数据库索引或者操作系统的文件系统。其实就是不再在非叶子节点保存数据了, 这些节点只是负责提供索引信息。这样子,B 树的内部就不用保存数据了,同等情况下,内存中可以一次性保存更多的索引, 减少了磁盘 IO 的次数。同时,因为数据都在叶子节点,查询路径的长度都是相同的,查询效率更加稳定。
B 树是通过节点的分裂与合并来保证树的平衡的。插入数据的时候,如果节点超过了容纳数量上限,就要进行节点的分裂操作, 然后把一个数据上升到父节点中。删除数据的时候,如果须要的话就进行节点的合并。
R 树
R 树其实就是从一维的索引到多维索引的一个扩展。二叉树和 B 树索引都是只保存了一维的大小关系信息, 如果我们须要根据高维的信息进行排序索引的话,势必在每次查询中都要有很多高维信息的计算。
为了节省这些计算,就须要在索引中增加高维信息。用二维的区域来举例的话,R 树是像下面这个样子的。
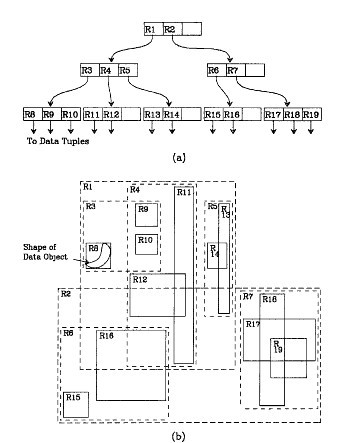
父节点和子节点之间,存在的是一种二维区域的包含关系(当然更高维度也是 OK 的),进行检索的时候也是根据这些关系, 减少查找的路径。但 R 树的插入和删除操作也是同样的分裂和合并节点,只不过边界的计算会多一些。
Summary
果然没学过数据结构错过了很多很有趣的东西啊,是时候找时间看看《算法导论》了。