翻译《Elements of Scale: Composing and Scaling Data Platforms》
尝试一篇翻译,果然对自己来说太难了。英文差是一个方面,但是对数据库不怎么了解才是硬伤。
作为软件工程师,我们不可避免地受到我们使用的工具的影响。语言,框架,甚至是流程(原文为 processes) 也会和我们一起塑造塑造软件。
同样的,数据库,也会对我们在应用中如何处理扩展性,如何共享状态产生影响。
这几十年,业界,特别是各种小开源项目,已经探索了很多种不同的方向。他们相互组合, 形成了一套一套的工具。每个组件都依赖于一些特定的硬件或者系统,以至于他们解决问题要不太笨拙, 要不太具体。
现在的数据平台,有着很大的复杂性。从增加缓存层,polyglotic persistence (不知道中文应该翻译成啥, 大概是多语言持久化?),到数据管道,有各种各样的技术。他们的思路各不相同,有些还是很有意思的。
本文的主旨是说明一些流行的技术的原理,还有他们这样选择的原因。我们会从一些基础的组成部分开始讲起, 方便我们后面能把他们组合成更大规模的东西。
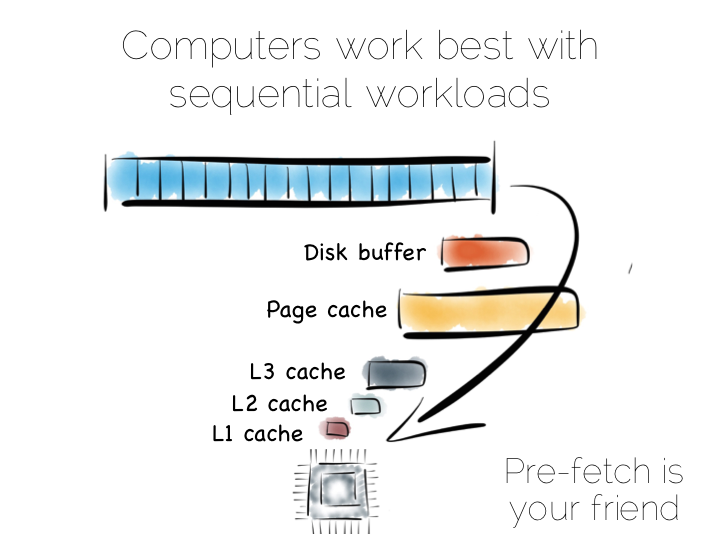
本质上来说,当我们处理数据的时候,我们实际上实在安排位置,相对与 CPU,相对于其他数据的位置。 连续得访问数据是很重要的,CPU 擅长连续数据的操作,因为这是些可预测的。(这一段感觉翻得好奇怪)
当我们连续地从硬盘获取数据,数据会被预读到磁盘缓存(disk buffer),页面缓存(page cache), 不同级别的 CPU 缓存中。这对性能会有很大的影响。但预读机制对随机寻址没有什么帮助, 无论是在内存磁盘还是网络请求。事实上,预读还妨碍了随机寻址的,各种缓存以及前端总线里填满了并不会被用到的数据
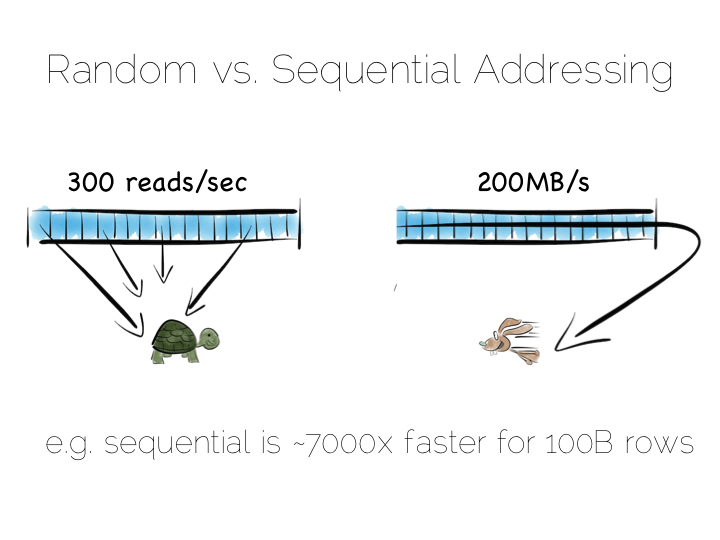
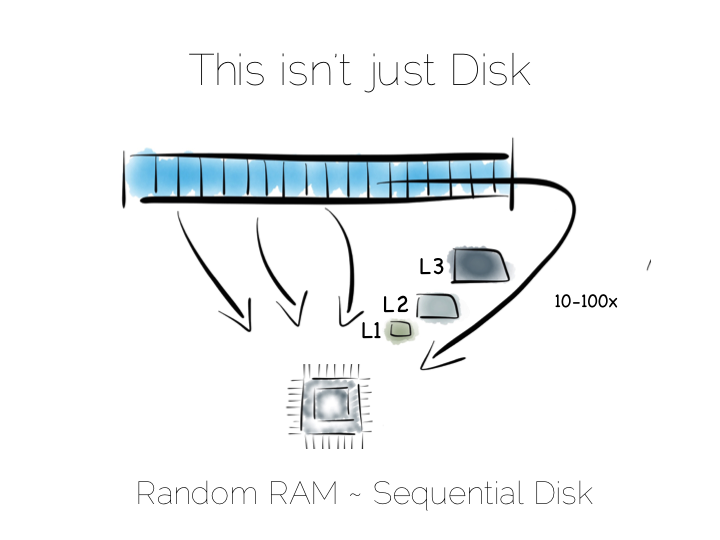
通常我们认为硬盘的读取速度是很低的,主内存相对来说就快多了,但事实并非完全如此。 对主内存来说随机寻址和顺序读写之间有着一两个数量级的性能差距。特别是当使用帮你管理内存的编程语言时, 情况可能会更糟糕。
从硬盘上读取连续数据流的性能是高于在内存中随机寻址的。所以,如果我们能安排连续的读取, 硬盘并不总是像我们想的那样非常缓慢。SSD 硬盘展示了另一种思路,特别是使用了 PCle 技术。 但无论如何,缓存机制对这两种存取方式还是有很大影响。
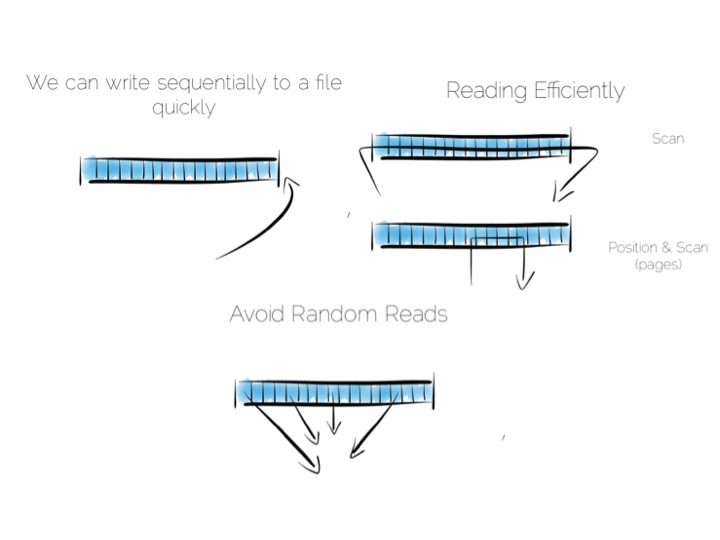
现在让我们先来做一个思维试验,建立一个简单的数据库。我们从最简单的,一个文件开始。
我们想要保持顺序的读写操作,因为这样有利于发挥硬件性能。往文件末尾顺序地添加内容很简单。 通过扫描整个文件来进行读取操作。这些操作都可以通过穿过 CPU 的数据流来完成, 过滤、聚合甚至更复杂的操作都可以做到,exciting!
那数据更新操作又如何呢?
我们有两种选择,我们可以在数据原来的位置上进行更新, 这可能须要数据定宽,不过对于我们的思维试验来说,可以先忽略这个问题。 但这样的更新方式意味着须要随机的 IO,会对性能产生影响。
或者我们可以这样,直接把更新添加到文件的末尾,等我们读的时候再处理废弃的值。
所以这里我们遇到了第一次选择,是添加修改到日志文件,保持顺序读取,还是说原址更新, 但忍受 300/s 的写速度(假设我们直接进行底层操作)。
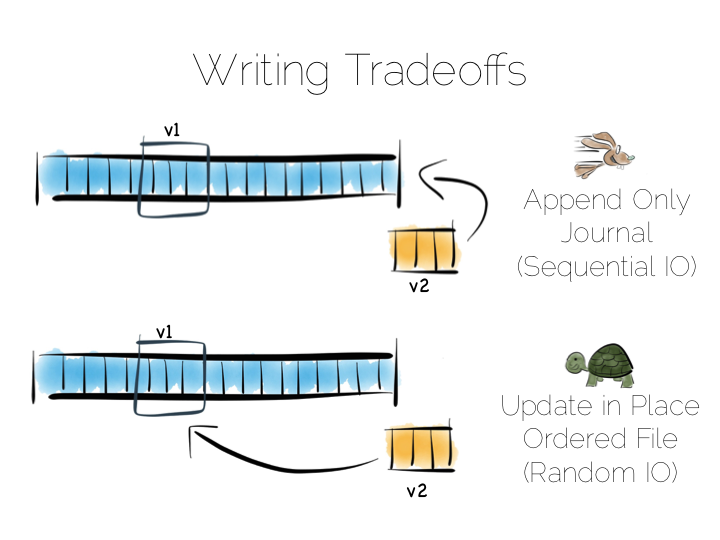
在实际操作中,扫描整个文件来进行读操作是效率很低的。可能我们只是要读几个 GB 的数据, 即使最快的硬盘也要花几秒钟。数据库的初始表扫描也是这样做的。
但我们平时须要的,通常是一些特定的东西,比如说我们想找客户”bob”。这时候扫描整个文件, 就有点太过了,我们需要建立索引。
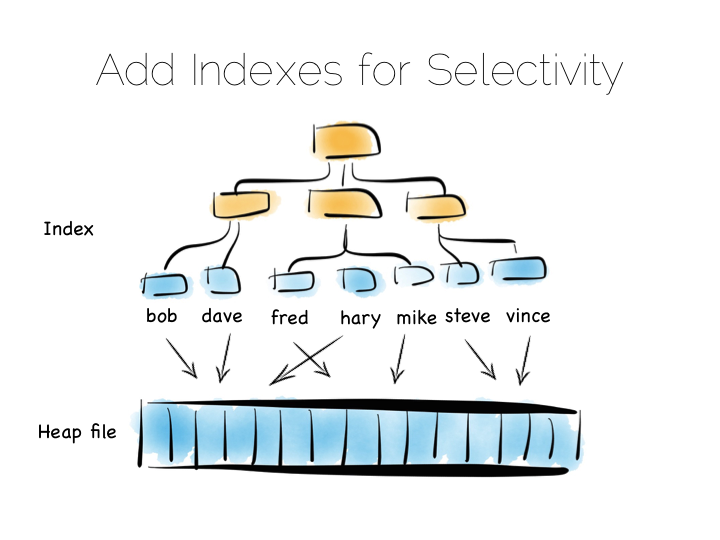
索引也有很多不同的类型供我们选择。最简单的,就是建立一个拥有定宽值的有序数组, 在这个例子中,是客户名,带着对应的数据在文件中的偏移量。有序数组可以用二分法来搜索, 当然也可以用某种树,或者位图索引、哈希表、术语索引等等,不过这里我们画了一棵树。
像索引这样的东西,其实是在我们的数据上强加了一个结构。数据按照顺序排列,所以我们读的时候, 可以很快就找到他们。这么做的问题是,当我们有数据流入的时候,就无法使用连续的方式写了。 我们只在文件末尾添加内容的写优化就失效了,须要对这种散乱的文件系统做新的增强。
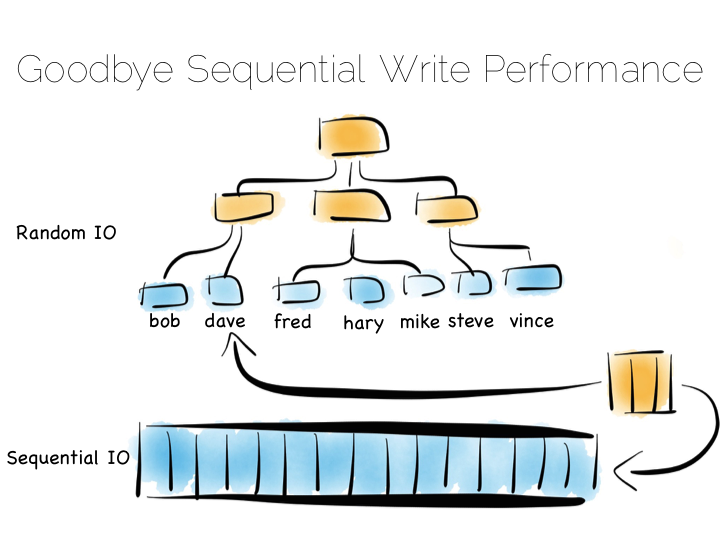
任何在数据表里面设置了大量索引的人对这个问题都不会陌生。如果我们使用一个转转的磁盘驱动器, 为了保证整个索引的完整性,转速可能会下降 1000 倍。
幸好这个问题还是有几种解决方案的。我们准备讨论其中三种,代表了三个方向。他们比在实际应用中简化了一些, 不过我们只关注概念的层面,方便后面理解更复杂的东西。
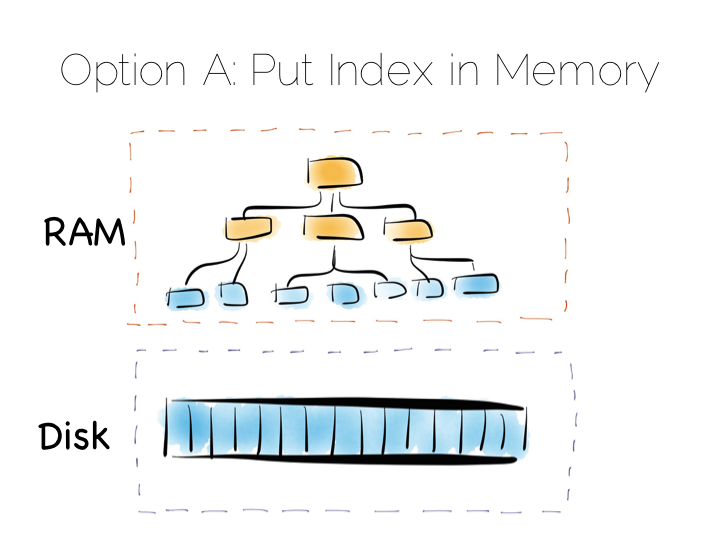
我们的第一种方案只是简单地把索引放到主内存中。这样,随机读写的问题就留在 RAM 中, 堆文件就在硬盘上保持顺序读写。
这是一个简单有效的方案,很多数据库采用这种方法,比如 MongoDB, Cassandra, Riak 等等。 它们通常使用的是内存映射文件。
但当我们的数据量超过了内存容量,这种策略就不再适用了。 特别是我们的数据是很多小对象的时候,我们的索引就会非常大。这样内存容量就成为了我们数据库容量的瓶颈。 当然对很多任务来说,这种策略已经足够了,但数据太大的时候,还是会有很大的内存负担。
另一种方案是,我们不再维持单一大索引,而是使用一组较小的索引。
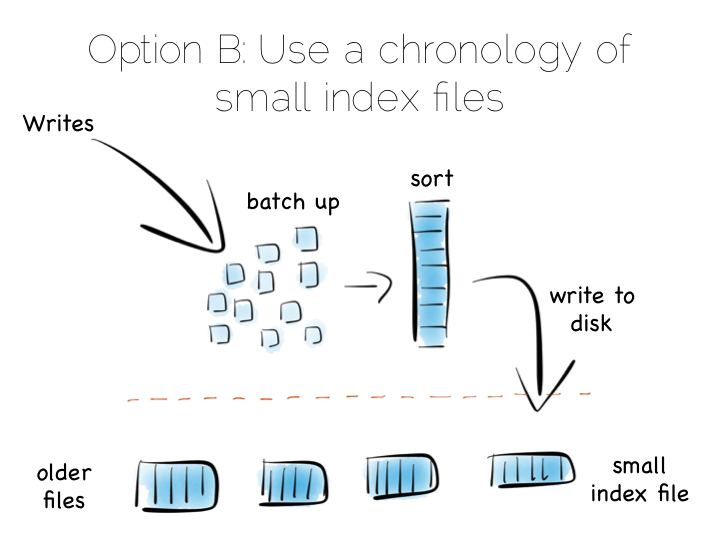
这个思路也很简单。我们先把写操作暂存到内存里面,攒了一定量之后,比如说攒了几 MB, 就把这些数据排序,做好索引,写到硬盘里面,作为一个独立的小索引。最后,我们就会得到一组有序、 不可变的小索引文件。
这个方案的有点是啥呢?我们的不可变文件可以顺序读取,进行流式传输。这样我们就又可以享受超高的写速度, 又不必把索引放到内存里面。
当然,这样做也有缺点。执行读操作的时候,我们须要查阅许多小索引。 所以这个方案其实是把随机写的问题转移到随机写上。然而很多情况下,这样做也是很有优势的, 随机读优化比随机写优化容易多了。
在内存里面维持一个小索引或者使用 Bloom Filter 算法,都可以在读操作的时候, 只用很少的内存资源来确定一个小索引是否须要被检查。这样我们就有了和使用单个大索引几乎相同的读性能, 同时保持快速的顺序写入。
在实际应用中我们还须要处理偶发的更新操作,不过通过顺序读写就可以解决。
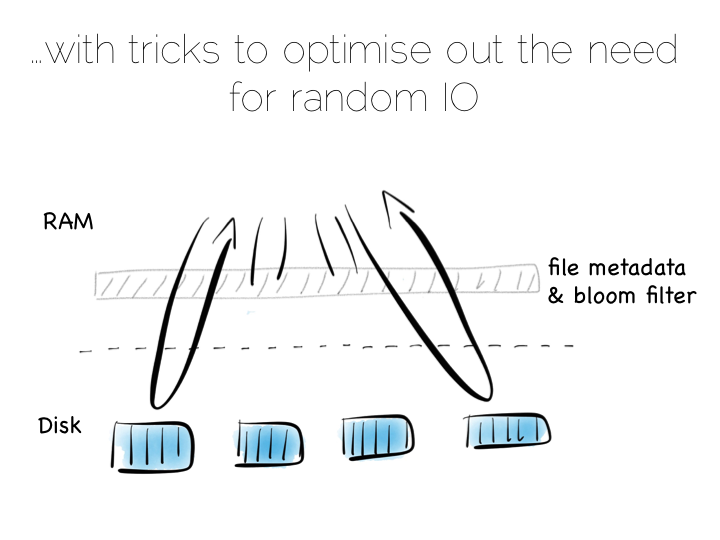
我们创建一个叫做Log Structured Merge Tree 的东西(LSM-Tree)。很多处理大规模数据的工具使用了这种方法,如 HBase, Cassandra, Google 的 BigTable 等等。这种方案很好地平衡了读写性能和内存开销。

这样我们就通过在内存储存索引或者用写优化的索引结构(比如LSM)来避免低效率的随机写操作。 当然还有第三种方案,更暴力的方法。
回想一下我们一开始说的单个文件的例子。我们可以方便地读取整个文件,这给我们重新组织他内容的机会。 第三种方法就是我们按列来组织数据,而不是行或者是流的方式,因为只有列才需要查询索引。 这种方法成为 Columnar 或者 Column Oriented (不知道应该翻译成啥, 柱状数据库?)。
(这列存储方法跟 Big Table 模式同名,但其实是两种不同的东西)
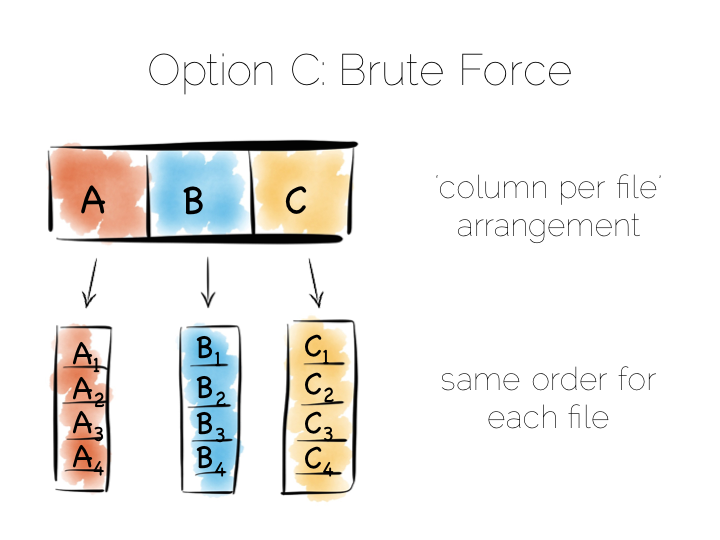
Column Orientation 的思想也很简单。我们把数据按列分开,每列存在一个文件里, 而不是像之前那样把很多行数据放到一个文件里。
我们维持这些列文件中的数据顺序相同,也就是某一行在每个列文件中的偏移量是一样的。 这点很重要,因为一个 query 通常要一次性读多列的数据。这意味着我们须要动态地进行列拼接。 如果每一列的数据相同,我们就可以通过一个简单的循环完成,CPU 负载不高,而且很方便缓存。 很多实现方案使用向量化来优化拼接操作和过滤操作。
这样写操作就可以简单的在文件末尾添加,效率比较高。但是我们现在就会有很多的文件须要更新, 相当于每一列都需要单独一次写入。常见的解决方案是使用上面提到的 LSM 类似的方法来批量处理写操作。 许多采用 Columnar 的数据库还会做一个整体的排序来优化读操作性能。
通过按列拆分数据,我们减少了需要从硬盘读取的数据量,因为通常我们读的是所有列的一个子集。
另外,单列内的数据通常会比较好压缩。特别是如果我们知道列的数据是特定的一个类型, 就可以用 run-length, delta, bit-packed 之类的这些高效的编码方式。某些编码谓词也可以直接用未编码的流上 (这句不知道怎么翻For some encodings predicates can be used directly on the uncompressed stream too)。
对须要大量扫描的任务来说,比如求和,求平均值,最小值,分组操作等,这是一个不错的解决方案。 这和之前提到的使用堆文件与索引的方法很不一样。要理解这一点,可以问自己一个问题, 这种柱状方法和『堆文件加索引』这种索引加在每一个字段上的方法区别是啥。
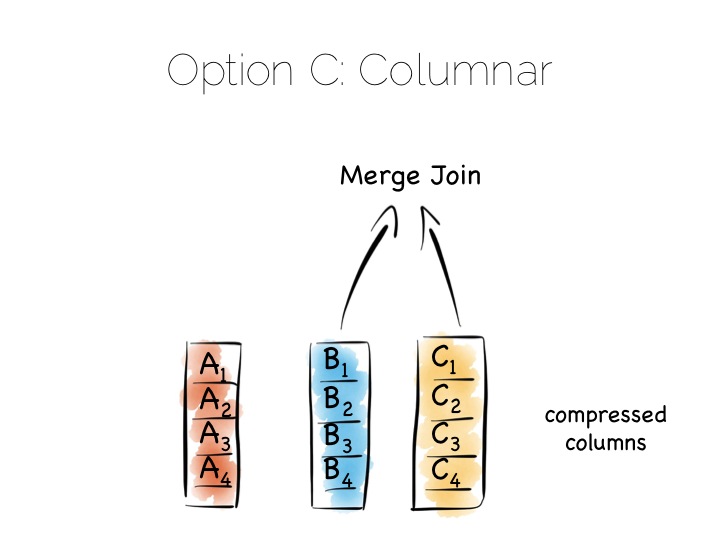
问题的答案就是索引文件的顺序。像 BTrees 之类的结构,是按照索引的字段排序的, 拼接两个字段的数据是一个流操作。但如果是堆文件加索引的模式,索引找到第一个字段之后, 接下来就需要一个随机读的操作了,通常会比拼接两个有相同排序的列效率低。 我们又一次借助了顺序访问来优化性能。
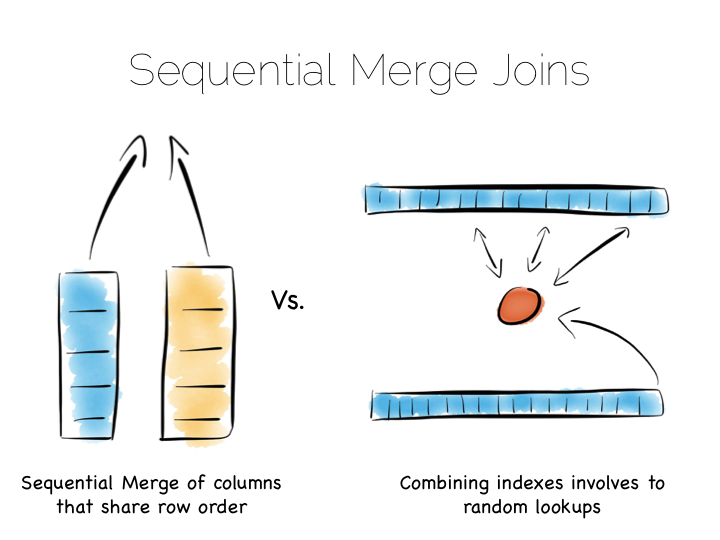
这些优秀的技术成为数据平台的基石。我们其中某种作为核心,来解决问题。
保存堆文件的索引到内存中这种方式,很受各种 NoSQL 存储的欢迎,像是 Riak, Couchbase 还有 MongoDB,甚至不少关系型数据库也使用这种方式。简单又有效。
为大规模数据设计的工具一般会使用 LSM 方式。在使用磁盘的基础上,能保持一定的读写性能。 HBase, Cassandra, RocksDB, LevelDB 甚至 Mongo 现在也支持这种方式。
柱状文件的引擎在 MPP 数据库中用得比较多,像是 Redshift 或者 Vertica, 还有使用 Parquet 的 Hadoop 堆栈。这些都是须要处理很多数据遍历问题的引擎,集合处理是他们的主场。
还有其他的,像 Kafka 适用于简单的,硬件性能良好的报文协议。最简单的报文,就是单纯地添加内容到文件末尾, 或者从预定的偏移读取数据。从特定的偏移量读取数据,下次再从之前读操作的结尾开始读, 是一种高效的顺序 IO。
这和打部门的消息中间件不同。比如 JMS 和 AMQP 需要有索引,用来管理选择器、会话信息之类的。 也就是说他们更像是一个数据库而不是一个文件。Jim Gray 在他 1995 年发表的《Queue`s are Databases》里面提出了这一点。
所以上面提到的方案,做出了不同的权衡,但都保持了简单的原理和很好的硬件兼容, 也就是说很容易扩展。

我们已经讲过了一些存储引擎的核心方法。虽然实际应用中会复杂很多,我们做了一些简化, 但弄清概念还是很有用的。
扩展一个数据平台不只是考虑存储引擎,还要考虑并行的因素。
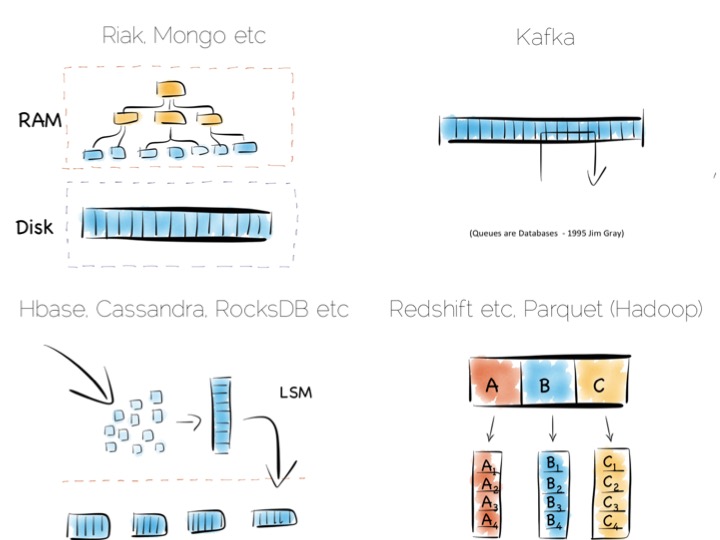
当我们讨论多个机器上的数据时,我们主要要面对两个问题,分区和复制。分区有时候也称为分片, 在随机读写和高负载的情况下都能表现得不错。
如果我们使用基于散列的分区模式,就要在多个机器上创建一个公用的散列函数,原理跟哈希表差不多, 确保每个 bucket 位于不同的机器上。
当须要读一个数据的时候,我们就可以通过散列函数直接找到存储着它的那个机器了。 这种方式有着极好的可扩展性,这是唯一在客户端请求增长的时候能有线性扩展性的方式。 请求被隔离在一个独立的机器上,每个请求只由集群中的一个机器进行处理。

我们也可以通过分区来提供批处理服务,比如聚合函数或者更复杂的算法聚类、机器学习什么的。 关键点在于我们使用广播的方式让所有机器同时运行。这让我们能在更短的时间内完成一个高计算量的问题。
批处理服务面对大型问题的时候表现得很好,但是并发性很差,因为它执行的时候会耗尽集群上的所有资源.
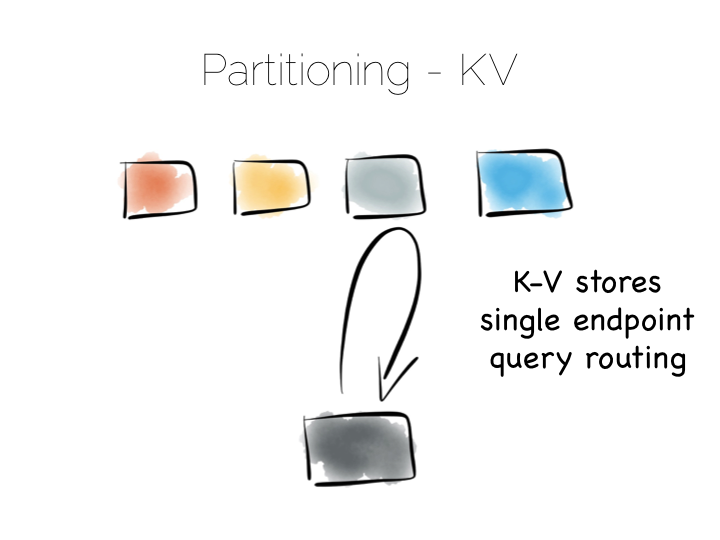
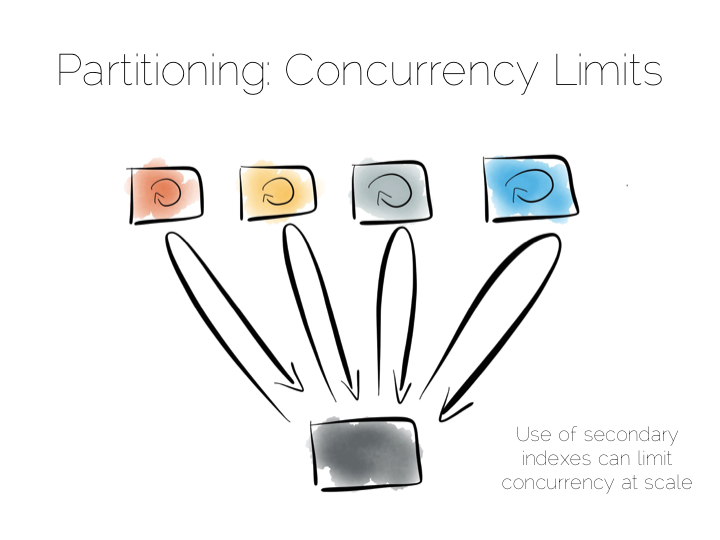
所以现在我们有两种极端策略,一种是直接访问一个机器,另一种是广播。我们须要小心的是, 位于两者中间的策略。比如在很多跨机器的 NoSQL 存储中使用的辅助索引机制。
辅助索引是一个不在主键上的索引。这意味着数据并不按照索引来进行分割,也就是通过散列函数来路由不再可行了。 我们必须向所有机器广播请求。这样并发性就很差了,每一个查询都回涉及每个节点。
因此很多键值存储库很抗拒添加辅助索引。HBase 和 Voldemort 是两个例子。 也有很多其他数据库,如 MongoDB, Cassandra, Riak 使用了辅助索引。辅助索引虽然有效, 但重要的是理解它对系统并发性的影响。
造成性能瓶颈的原因是备库。你可能很熟悉使用异步保存的数据库或非关系型数据库的备库了。
实际应用中,备库可能是透明的(只用来做恢复),只读的(并发读),或者是可读可写的 (增加容忍分区)。你须要根据系统的一致性要求进行选择权衡。这是 CAP 定理决定的。
关于一致性*的权衡背后是一个重要的问题,数据的一致性,在什么时候是最重要的。
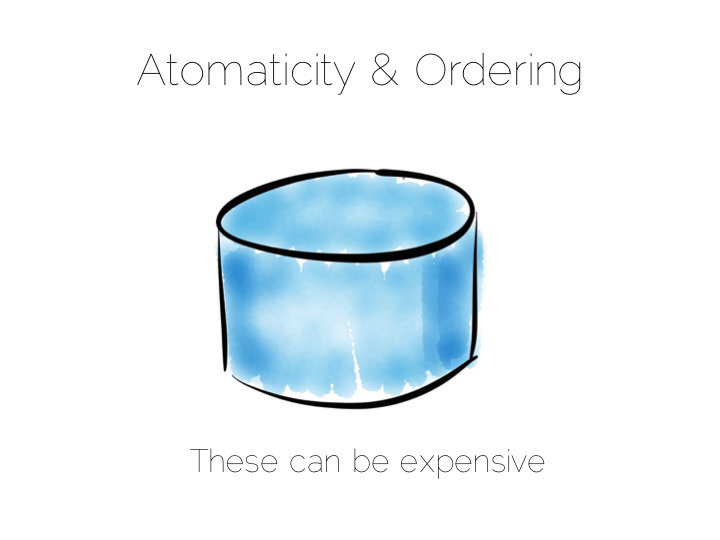
实现一致性的代价是很高的。在数据库中 ACID 是由链式操作保证的,所有操作按顺序执行。 这实际上是成本很高的一件事请,所以很多数据库甚至都不对此提供一个隔离级别。
总得来说就是,如果想要在分布式写的系统中实现一致性,那系统的性能就会变得非常差。
(* 注意,一致性这个词通常有两种用法,分别是 ACID 中的 C 和 CAP 中的 C。这两者是不同的, 我这里使用的是 CAP 的定义:所有节点在同一时间访问统一份最新的数据)
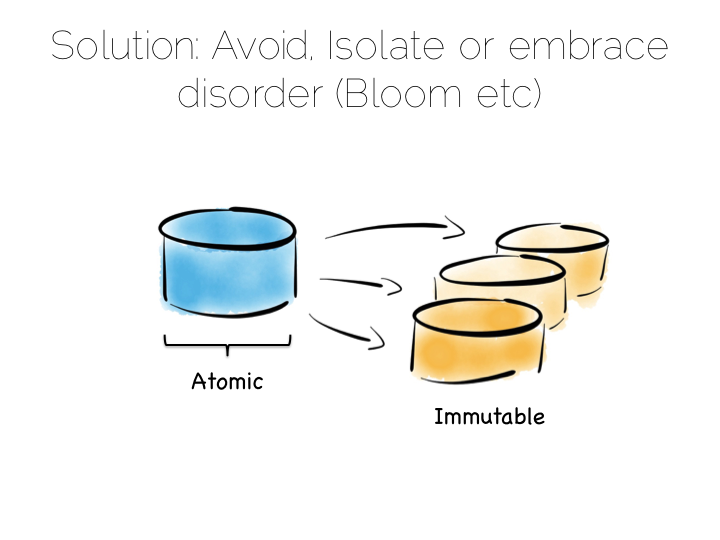
解决一致性问题的方案很简单,就是避免它的出现。如果真的无法避免,也要把它隔离在尽可能少的机器上。
避免一致性问题有时候还是很简单的,特别是当你的数据是一个不可变流的时候。比如说一组 web 日志,他们并没有一致性的要求,因为他们并不会发生变化。
但有些场景还是有保证一致性的必要的。比如说在两个账户之间转账,或者非交换性的使用折扣券之类的。
通常情况下,一些看起来须要保证一致性的场景,其实不一定须要。如果一个动作能从一个状态突变转换成一组新的记录, 我们就能避免这种易变的状态。比如说我们要把一个交易标记为有诈骗嫌疑的。那我们可以直接加一个新字段, 然后更新它,或者我们可以简单地记录一个操作流,链接到原始交易。
因此在一个数据平台中,要么完全避免一致性的需求,要么将它隔离到一个笑得范围内。 一种隔离方法是只使用一个写服务,另一种是物理隔离,区分出可变世界和不可变世界。
像 Bloom/CALM 这些方案推崇一种思想,在默认的情况下拥抱操作的无序,只有当须要顺序的时候, 才保证顺序。
现在,我们有了这些须要进行取舍权衡的要素,要如何把他们放到一起,组建一个数据平台。
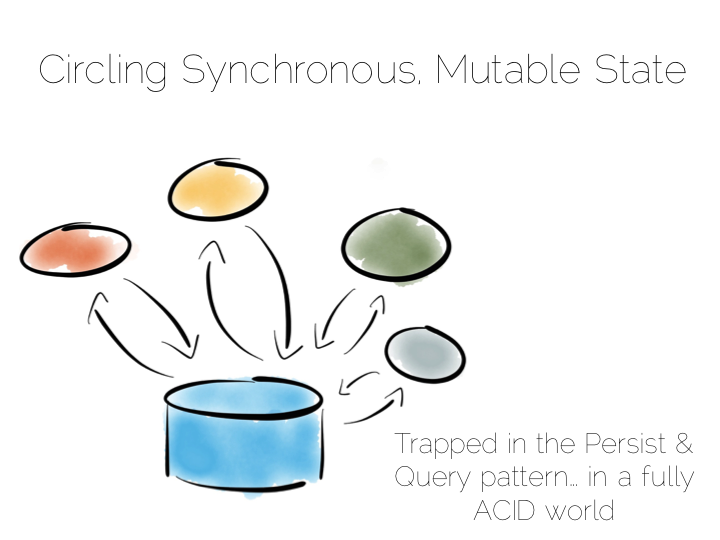
一个典型的应用架构看起来可能像下面这个一样。我们有一些操作,会写数据到数据库, 然后再把数据读出来。对很多的简单工作,这样就够了。很多成功的应用采用了这种模式。 但我们知道,当问题的规模变大的时候,它可能就不怎么灵光了。在应用程序中, 我们可能使用消息机制、actors、负载均衡等方法来解决。
另一个问题是,这样其实把数据库当成了一个黑盒子。数据库应该是很聪明的,提供了很多机制, 让我们扩展 ACID 的世界。默认的使用方式是很安全的,但当我们面对更大的规模的时候, 它的性能有可能会因为我们过度的需求而受到移植。

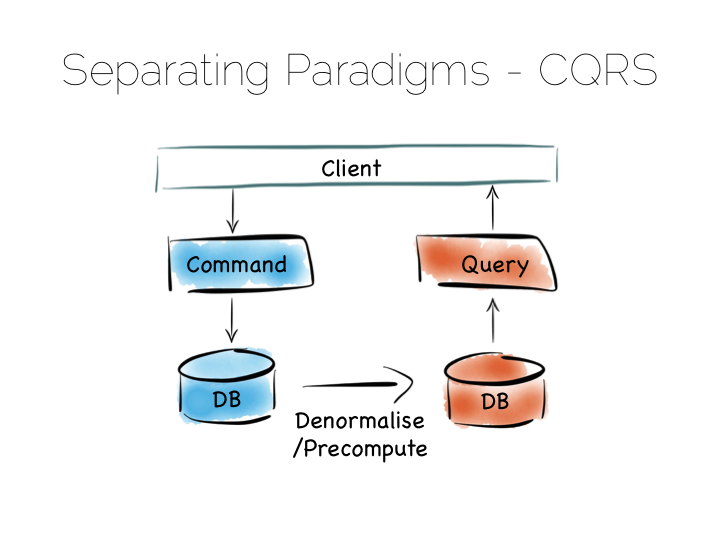
一个简单的方案是 CQRS (命令查询职责分离)。
另一种简单的方法是,我们把读写工作分开。对写操作进行专门的优化,比如简单的日志文件。 同时读操作也有相应的优化,像 Goldengate 这样的工具,或者是 MongoDB 中的 Replica Sets 都是用来解决这个的。
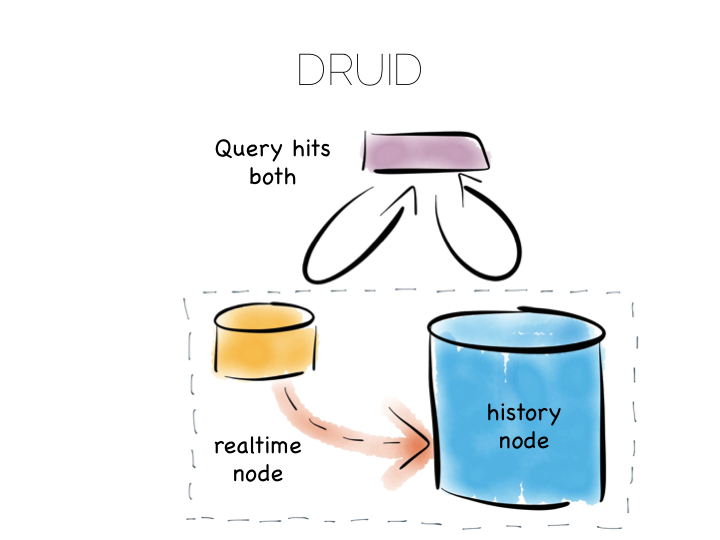
许多数据库在底层做了类似的优化。比如说 Druid。Druid 是一个开源、分布式、事件序列、 柱状的分析引擎。柱状存储在处理大块的输入时性能最好,数据被存储到多个文件中。 为了提高写操作的性能 Druid 储存数据到一个做了写优化的空间,然后随着时间的推移, 逐步把数据转移到做了读优化的空间。
当 Druid 被请求的时候,它会访问读优化和写优化两部分,结果会被组合到一起返回给用户。 Durid 利用在每条记录上的时间标记来确定操作顺序。
这样的组合提供了类似 CQRS 一样的效果,但又只暴露一个抽象的数据库接口。
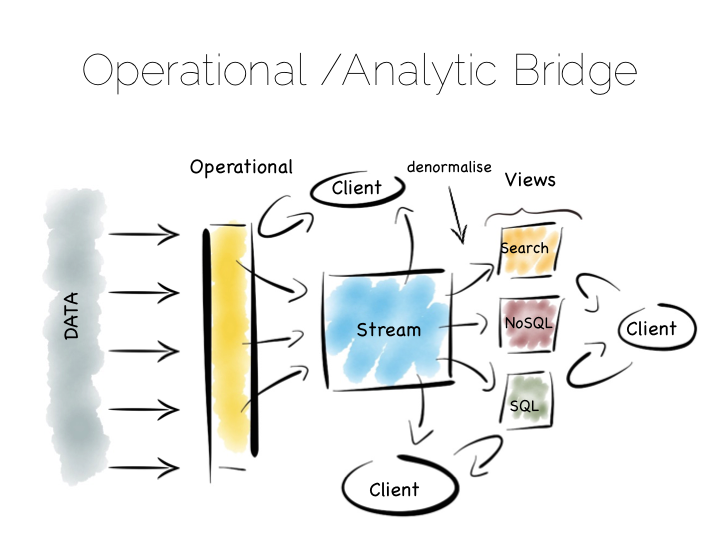
另一种方法是使用 Operational/Analytic Bridge。读写视图通过事件流来分隔。状态流会被永久保存, 所以异步请求可以通过重组和回放来响应。
前端的结构提供同步的读写操作,可以是简单的读取刚写的数据,也可以是复杂的 AID 事务。
这一段好难The back end leverages asynchronicity, and the advantages of immutable state, to scale offline processing through replication, denormalisation or even completely different storage engines. The messaging-bridge, along with joining the two, allows applications to listen to the data flowing through the platform.
这种模式很适合中型规模的开发,拥有至少一个可变视图的需求。
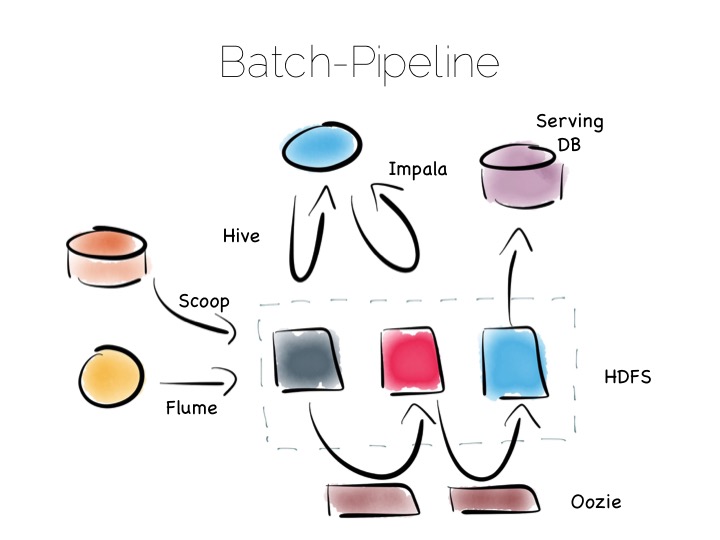
如果我们能将系统设计成一个不可变的世界,那它就能在大数据和复杂分析下表现得更好。 使用 Hadoop 对咱的批处理管道就是一种典型的应用。
Hadoop 的优势在于它非常齐全的工具集,无论你想要快速读写、低成本存储、批处理、 高吞吐量消息发送还是提取分析数据,Hadoop 的生态圈都有很好的实现。
批处理管道架构从各种源获取数据,将他们提取到 HDFS(Hadoop分布式文件系统), 对源数据进行一定优化。数据可以被补充、清洗、特化(denormalised 不知道应该翻成啥)、 聚合、转成一种读优化的格式(如 Parquet)、转到server 层或者传入 data 层。
这种架构非常适合不可变数据,大容量的读取和处理。但想一想 100 TBS 以上的数据, 这种结构就会变动很缓慢了,通常要花几小时的时间才能完成处理。
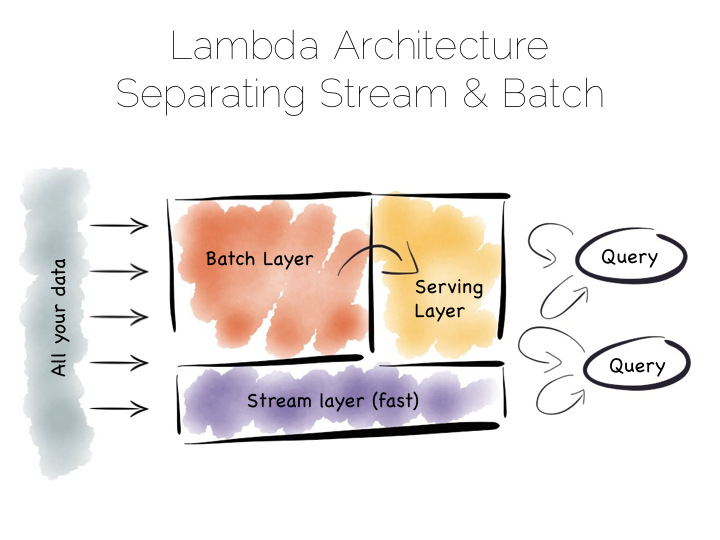
批处理管道的问题在于,我们通常不想等一两个小时来获取数据。常用的解决方案是, 在旁边再加个 streaming 层。这种方案也被称作 Lambda Architecture。
跟上面的一样,Lambda Architecture 也维持一个批处理管道,但同时用一个 streaming 层绕过他。这有点像在一个拥堵的小镇旁边建造一条旁路。这个 streaming 层通常会使用一些流处理工具, 如 Storm、Samza 等。
Lambda Architecture 关注的一点是,我们通常希望很快得到一个近似的结果,最后再得到准确的答案。 所以 streaming 层绕过批处理,提供一个在流窗口内能提供的最优解,这些会被写在 server 层。稍后批处理管道计算出精确的结果,再对此进行覆盖。
这是一个在精度和响应速度上取得巧妙平衡的方法。如果流处理和批处理都被进行了二进制编码, 某些实现可能会受到一些影响(这句好奇怪感觉自己没理解好代词),但通常来说, 这种机制可以简单地抽象成通用库重复使用。比如说 Python 或者 R 语言的库会包含这些逻辑。 像 Spark 这样的系统提供了流和批处理的功能(虽说在 Spark 中的流其实是微型的批处理)。
这种模式适合大容量的,如 100TB+ 的数据平台,结合了流和丰富的批处理解析函数。
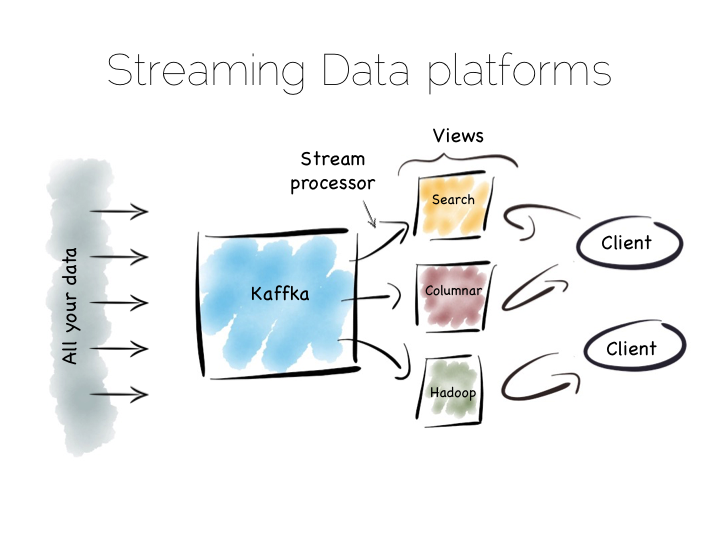
还有另一种方法来解决批处理管道缓慢的问题。这种方式有时候被称为 Kappa 结构。 其实我觉得这个名字有点不符。所以我会用另一个术语『流数据平台』(原文为 Stream Data Platform), 这也是一个常用的名称。
流数据平台翻转了批处理的位置。数据被储存在一个扩展的消息系统,或者日志,像是 Kafka, 而不是存在 HDFS(Hadoop分布式文件系统),然后再去用批处理过滤它。这就成为了一个基于记录的系统, 数据流实时处理,然后,创建三视图、索引、服务层、数据集等。
这其实跟 Lambda 结构中的 streaming 层类似,只不过去除了批处理层。显然,这种模式要求消息层能够存储、 推送非常大量的数据,还有一个很强大的流处理器来对数据进行处理。
天下没有免费的午餐,对于困难的问题,流数据平台相比等价的批处理系统可能会慢一些, 但从『储存然后处理』到『处理流数据』的转变让我们有更大的机会更快得到结果。
最后,流处理平台可能会遇到应用集成的问题。这是一个棘手的问题,像 Infomatica Tibco 和 Oracle 之类的大厂多年来一直在寻求解决方案。虽然有很多优化,但都没有达到质变的水平。 应用继承还是处在寻找真正可行方案的阶段。
流数据平台提供了一种有趣的可能的解决方案。通过使用 O/A 桥,获得异步存储格式和新建视图的能力, 同时隔离了一致性的要求。
伴随着这些拥有不变性的日志记录系统,像 Kafka 这样的产品才能够有足够的空间做核心历史纪录。 这意味着数据恢复可以通过回放和再生完成,而不是备份一个一个的检查点。
类似风格的方法已经在很多大型项目,如 Goldengate,中用来移植数据到企业数据仓库, 或者是新的数据池。他们经常被复制层吞吐量不足,复杂变化的管理困扰。 第一个问题看起来应该会很快解决,但是剩下的还没有很好的办法。
~
我们开始的时候,关注的是顺序读写。这是我们使用的组件重点考虑的问题。然后我们扩展这些组件, 问题的重点转移到了分区和复制。最后,我们关心的是在数据平台搭建的过程中,隔离一致性的要求。
数据平台其实就是用一个整体的结构来平衡这些独立的组件。从写优化到读优化,从受一致性约束到自由地使用流式、 异步、不可变状态,一步一步构建整个系统。
要完成这些,最重要的几点就是:图、事件、分布式的风险、异步。如果仔细解决,这些都是可控的。 当然还有很多其他的东西,像是工具、新型的大存储空间、各种各样的新老问题。